Databricks began as a research project at the University of California, Berkeley, with a simple goal: to help process large amounts of data more efficiently. The project was led by a team of researchers, including Matei Zaharia, Ali Ghodsi, Reynold Xin, Ion Stoica, and others at the AMPLab. They developed Apache Spark, a tool that drastically improved the speed and efficiency of big data processing. This focus on solving real data problems laid the foundation for what Databricks would eventually become.
As data volumes grew, so did the need for practical and scalable solutions. Recognizing this, the team officially launched Databricks as a company in 2013. They expanded its focus to include not just data processing but also data engineering and machine learning, making it an attractive option for businesses needing to manage, analyze, and derive insights from large datasets.
To further drive growth, Databricks strategically partnered with major cloud providers like AWS, Azure, and Google Cloud, simplifying integration for businesses. This move contributed to the company's rapid expansion. Today, Databricks is valued at over $43B billion, a testament to the founders’ vision of addressing real-world data challenges and their ability to adapt to the evolving needs of businesses.
Why Use Databricks?
Databricks is a powerful platform designed to help companies handle and analyze large amounts of data. From the start, its goal was to make it easier for organizations to process big data, whether for data engineering, machine learning, or analytics. By bringing all these tools together in one place, Databricks simplifies the process of cleaning, preparing, and analyzing data, allowing teams to work faster and make more informed decisions.
Companies' Success Stories
Databricks has been pivotal in transforming the data strategies of many leading companies. Here are a few success stories:
- AT&T: Modernized its data infrastructure with a cloud-based lakehouse, implementing over 100 machine learning models for real-time fraud detection, which cut fraud by up to 80%.
- Walgreens: Developed an intelligent data platform for real-time demand forecasting and personalized patient care, optimizing inventory, and processing 40,000 data events per second.
- USPS OIG: Centralized data analysis in a cloud-based data lakehouse, improving efficiency, reducing total costs by 40%, and enhancing postal operations through large-scale analytics and AI.
- Rivian: Managed vast data from Electric Adventure Vehicles (EAVs) to enhance vehicle health insights, democratize data access, and streamline predictive maintenance, supporting autonomous driving systems and boosting customer satisfaction.
Core Components of Databricks
The Databricks platform is built around several core components that simplify and enhance data engineering, data science, and machine learning workflows:
- Unified Data Analytics Platform
It allows teams across data engineering, data science, and business analytics to collaborate in one platform. From digesting data to performing analysis and creating visualizations, this component simplifies workflows and enhances efficiency by bringing all necessary tools together in a single workspace. - Delta Lake
Delta Lake ensures data reliability by supporting ACID transactions and scalable metadata management. It makes data lakes more dependable, allowing for consistent and accurate data processing even as datasets grow. - MLflow
MLflow manages the entire machine learning process. It helps teams track experiments, organize models, and deploy them efficiently, streamlining the journey from model development to production. - Databricks SQL
Databricks SQL enables users to run SQL queries on data stored in the data lake and create visualizations and dashboards. It provides an easy way to analyze data and generate insights that can be quickly shared across the organization. - Collaborative Notebooks
Collaborative Notebooks support real-time collaboration by allowing team members to write and run code, visualize data, and work together in multiple programming languages within a single document. This feature helps streamline the development and refinement of data projects. - Security and Governance
Security and Governance features protect data and ensure compliance with regulations. This includes user authentication, access control, data masking, and audit logging, all of which maintain the security and integrity of your data.
Databricks in action:

Databricks Architecture:
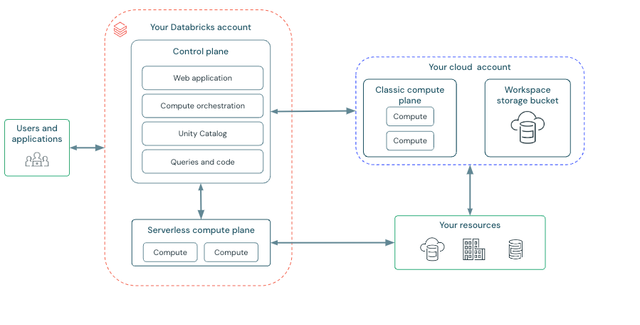
Databricks operates out of a control plane and a compute plane. The control plane includes the backend services that Databricks manages in your Databricks account. This includes the web application, compute orchestration, unity catalog, queries and code. The compute plane is where your data is processed, this can be a serverless compute resources running on databricks, or a classic compute resources running in the cloud provider.
Each Databricks workspace has an associated storage bucket known as the workspace storage bucket, which is inside your cloud provider for databricks.
Workspaces:
Workspaces in Databricks provide a collaborative environment for your teams to work together on data and analytics projects. Here’s how to manage them:
- Workspace Organization: Organize your workspaces by project, team, or department. This makes it easier to manage resources and permissions effectively.
- Shared Notebooks: Use shared notebooks for collaborative work allowing team members to collaborate on code, visualize data, and share insights in real time.
- Version Control: Integrate your workspace with version control systems like Git to track changes, manage code versions, and collaborate more effectively. This is essential for maintaining the integrity of your projects and ensuring reproducibility.
Notebooks:
Notebooks are the primary tool in databricks for creating data science and machine learning workflows and collaborating with the team. Provide a real-time coauthoring in multiple language, versioning, and built-in data visualizations.
Cluster:
A Databricks cluster isa set of configurations and computation resources where you run data engineering, data science, and data analytics workloads.
You run these workloads as a set of commands in a notebook and databricks make a distinction between all-purpose clusters and job clusters. You use all-purpose clusters to analyze data collaboratively using interactive notebooks and job clusters to run fast and robust automated jobs.
Permissions:
Managing permissions is crucial for maintaining the security and integrity of your data. Here are some steps to consider:
- Role-Based Access Control (RBAC): Implement RBAC to assign specific permissions to different roles within your organization. This ensures that users only have access to the necessary data and resources for their role.
- Cluster Policies: Control the configurations and permissions of clusters to prevent unauthorized access and ensure that clusters are used efficiently.
- Data Access Controls: Implement fine-grained access controls at the database, table, and column levels to protect sensitive data.
Integration of cloud providers with databricks:
Databricks can be used on every major cloud provider like AWS, Azure and Google Cloud. Easily connected with their respective services offerings for security, compute, storage, analytics and AI. Then you can choose the cloud provider that better satisfies your needs.
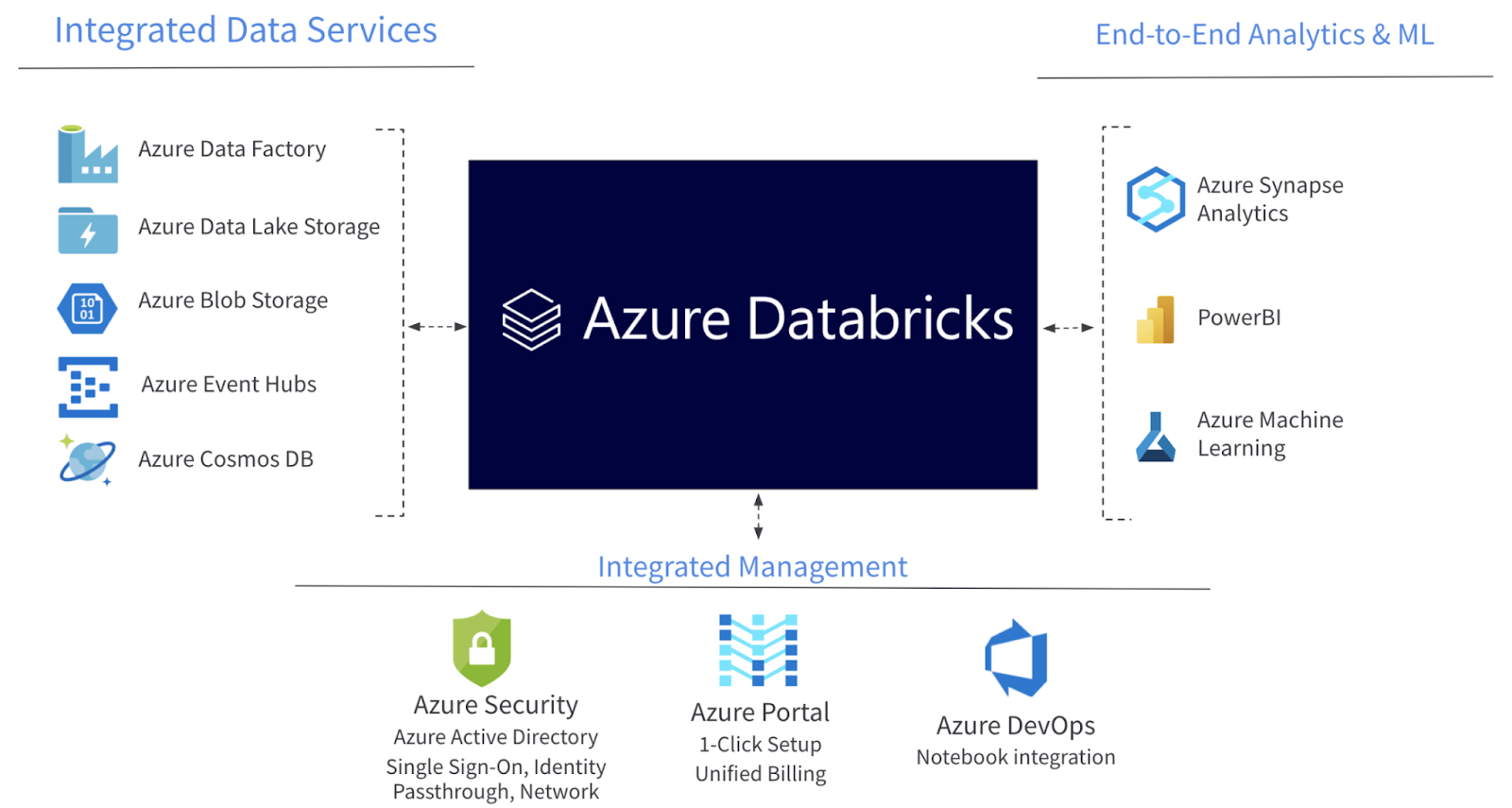
Azure
Azure Databricks is optimized for Azure and tightly integrated with Azure Data Lake Storage, Azure Data Factory, Azure Synapse Analytics, Power BI and other Azure services to store all your data on a simple, open lakehouse and unify all your analytics and AI workloads.
- 50x performance for Apache Spark™ workloads
- Millions of server hours each day across more than 34 Azure regions.
- Start with a single click in the Azure Portal, natively integrate with Azure security and data services
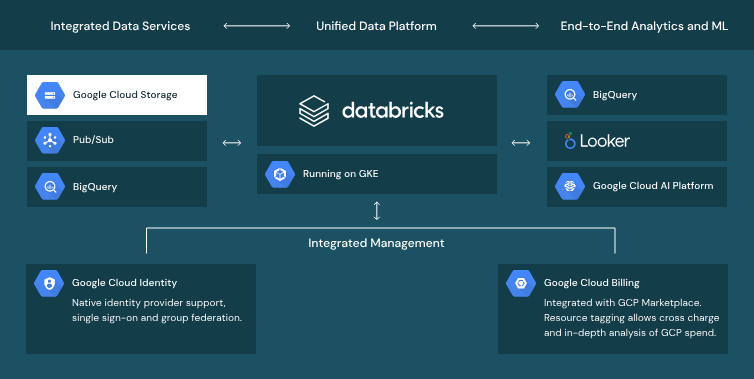
Google Cloud Provider
Tight integration with Google Cloud Storage, BigQuery and the Google Cloud AI Platform enables Databricks to work seamlessly across data and AI services on Google Cloud.
- Built on open standards, open APIs and open infrastructure so you can access, process and analyze data on your terms.
- Deploy Databricks on Google Kubernetes Engine, the first Kubernetes-based Databricks runtime on any cloud, to get insights faster.
- Get one-click access to Databricks from the Google Cloud Console, with integrated security, billing and management.
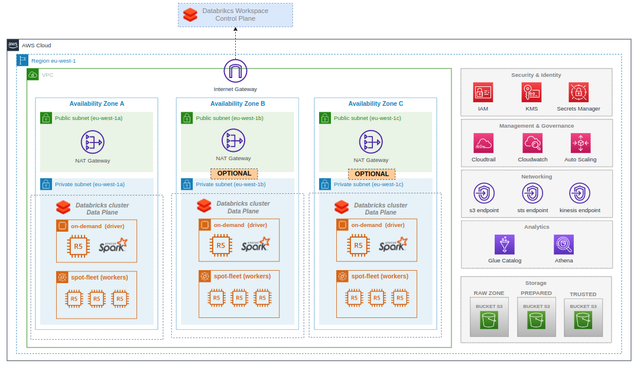
AWS
Databricks take advantage of clusterization on demand with EC2 resoures, with the security & identity and the management & governance of any aws resource.
- Databricks enables a single, unified data architecture on S3 for SQL analytics, data science and machine learning
- 12x better price/performance
- Thousands of customers have implemented Databricks on AWS to provide a game-changing analytics platform that addresses all analytics and AI use cases
Best Practices
Following best practices helps make your databricks efficient, scalable, and secure. Here are some tips to consider:
- Data Partitioning: Divide your data to optimize query performance and reduce costs. It helps to have more manageable segments based on certain criteria, such as date ranges or regions.
- Efficient Storage Formats: Use efficient storage formats like Parquet or Delta Lake. These formats are optimized for performance and can significantly reduce storage costs.
- Data Governance: Implement data governance policies to ensure data quality, consistency, and compliance. This includes data cataloging, lineage tracking, and auditing.
- Monitoring and Optimization: Continuously monitor your data warehouse for performance and cost. Use tools and features in Databricks to optimize queries, manage resources, and identify bottlenecks.
- Automated Workflows: Use Databricks' workflow automation features to schedule and manage ETL processes, data pipelines, and other repetitive tasks. This ensures that your data is always up-to-date and reduces manual effort.
Conclusion
Databricks is a comprehensive platform that combines the best features of data lakes and data warehouses, enabling organizations to reduce costs, accelerate AI initiatives, and simplify large-scale data management. With key tools like Delta Lake, MLflow, and Databricks SQL, along with robust security and governance features, Databricks enhances collaboration and efficiency in data workflows.
Its integration with AWS, Azure, and Google Cloud allows businesses to leverage the infrastructure that best suits their needs. By following best practices in data partitioning, storage formats, and governance, organizations can optimize the performance and security of their Databricks environment. In a data-driven world, Databricks provides the essential tools for achieving success through data and AI.